Transforming Data with Elasticsearch Ingest Pipelines

Have you ever needed to modify your data—such as renaming a field—before storing it? That’s exactly what Elasticsearch Ingest Pipelines are designed for. They allow you to perform common data transformations before the data is indexed. Ingest Pipelines support a wide range of transformations called processors. Each processor performs a specific action on your data such as renaming a field, removing a field, converting a field from one data type to another, pattern matching and many more.
In this blog post, we’ll walk through how Elasticsearch Ingest Pipelines can be used to preprocess and transform data at ingest time.
Let’s say you’re collecting login and logout events for security monitoring. Your raw data includes a field named username, but for consistency in your system, you want to rename this field to user.
[{
"timestamp": "2025-04-15T17:00:00Z",
"username": "darth_vader",
"event_type": "user-login",
"status": "success"
},
{
"timestamp": "2025-04-15T17:05:00Z",
"username": "bruce_wayne",
"event_type": "user-login",
"status": "failed",
"failure_reason": "invalid_password"
},
{
"timestamp": "2025-04-15T19:20:00Z",
"username": "darth_vader",
"event_type": "user-logout",
"status": "success"
}]Step 1: Create an Ingest Pipeline
First, we’ll create a pipeline called siem-data-ingestion with a single processor: a rename processor that renames the username field to user.
PUT _ingest/pipeline/siem-data-ingestion
{
"processors": [
{
"rename": {
"field": "username",
"target_field": "user"
}
}
]
}This ensures that any incoming document passed through this pipeline will have the username field renamed to user.
Step 2: Ingest Bulk Data Using the Pipeline
Next, use the _bulk API to upload multiple log events at once. Make sure to include the pipeline name in the query string:
POST /siem-logs/_bulk?pipeline=siem-data-ingestion
{"create":{"_index":"siem-logs"}}
{"timestamp":"2025-04-15T17:00:00Z","username":"darth_vader","event_type":"user-login","status":"success"}
{"create":{"_index":"siem-logs"}}
{"timestamp":"2025-04-15T17:05:00Z","username":"bruce_wayne","event_type":"user-login","status":"failed","failure_reason":"invalid_password"}
{"create":{"_index":"siem-logs"}}
{"timestamp":"2025-04-15T19:20:00Z","username":"darth_vader","event_type":"user-logout","status":"success"}Each document will automatically pass through the siem-data-ingestion pipeline, where the username field will be renamed to user.
Step 3: Verify the Ingested Data
You can verify that the documents were indexed correctly by running a search:
GET /siem-logs/_search
{
"query": {
"match_all": {}
}
}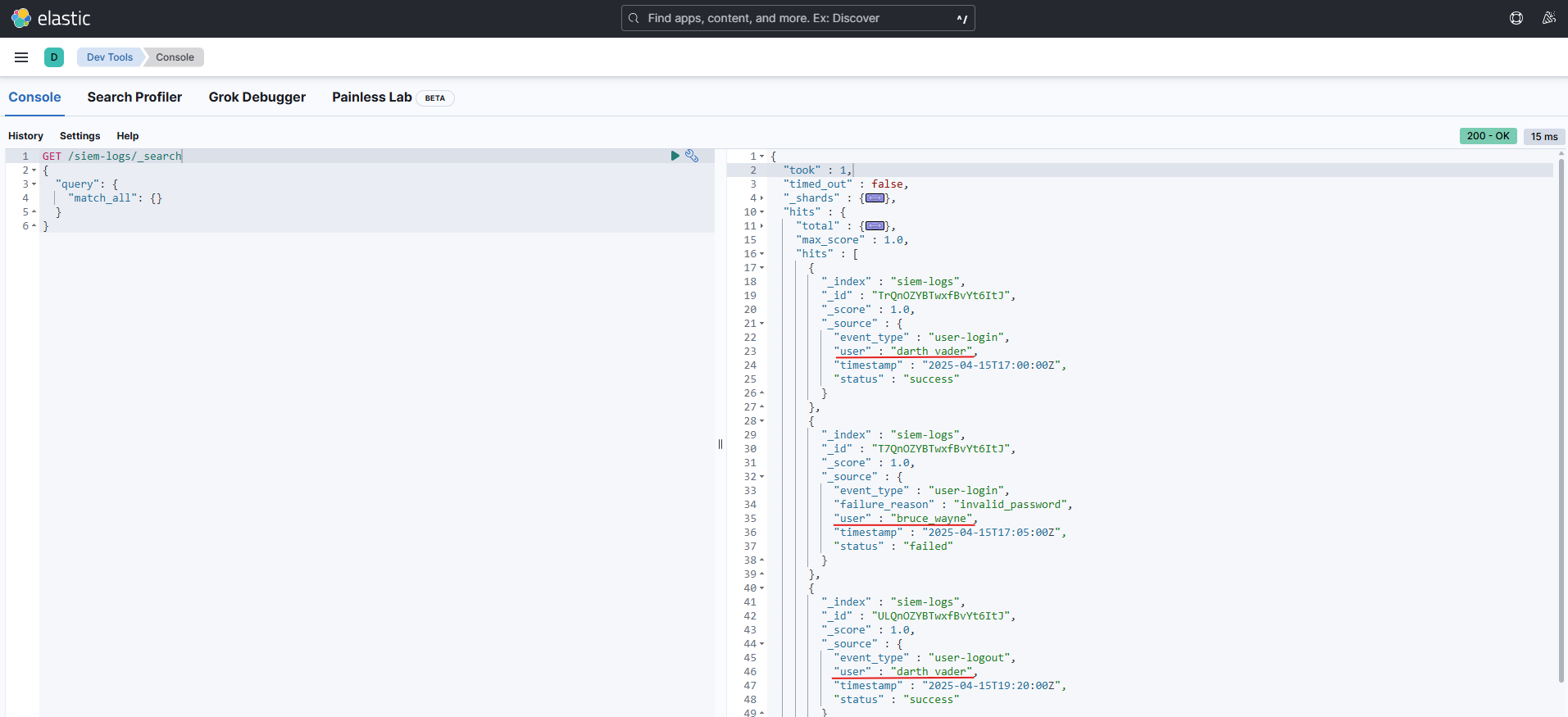
As you can see, the username field has been successfully renamed to user for all documents.
You can expand this pipeline with more processors like grok, date, remove, or set to handle more complex use cases.