Vector Search in Elasticsearch

In Elasticsearch, traditional search is text-based. Input text is analyzed—typically through tokenization, lowercasing, and other normalization steps—and the resulting tokens are stored in an inverted index for efficient retrieval. When you search, your query is processed the same way and matched against the stored tokens to find and rank the most relevant documents. Simply put, traditional search relies on keyword matching to find documents containing specific words or phrases.
Vector search focuses on capturing the meaning behind words by converting text into numerical vectors, called embeddings. Rather than matching exact keywords, it compares these vectors using techniques like cosine similarity to find documents with similar meanings.
Figure 1 illustrates the complete vector search workflow, from transforming raw data into vector embeddings to querying and retrieving the most relevant results.
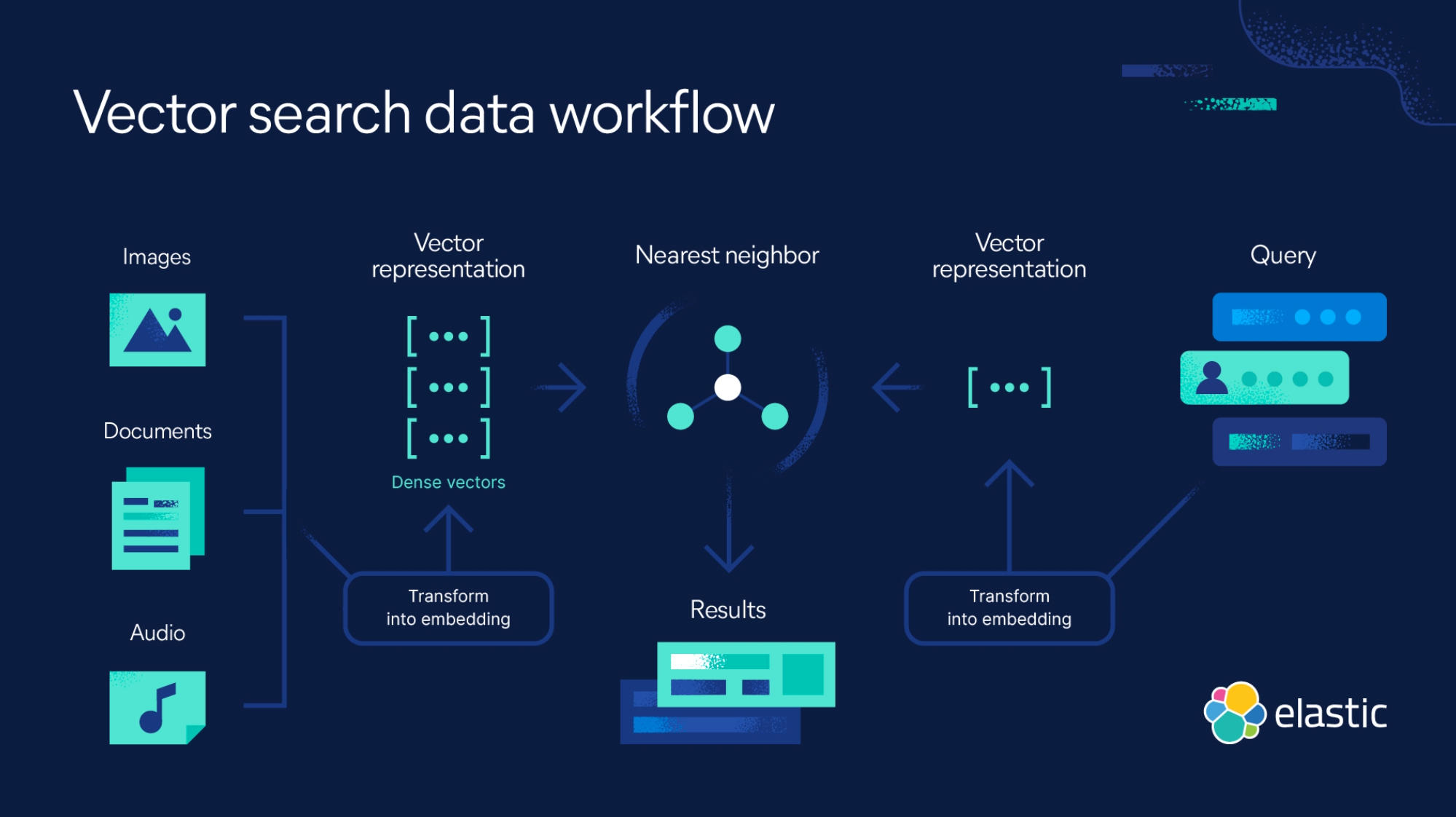
Figure 1: Vector search data workflow. Image credit: Elastic
What We'll Do:
- Prepare a dataset: In this tutorial we will work with a movies dataset that contains movie titles and descriptions
- Generate vector embeddings (using Azure AI Foundry): Use a pre-trained model (
text-embedding-3-small) to convert the movie descriptions into vectors - Setup Elasticsearch: Run an Elasticsearch instance with vector search enabled
- Index the data: Store each movie's description and its vector embedding in Elasticsearch
- Search using vectors: Given a user query, convert it to a vector and use Elasticsearch's k-NN search to find movies with similar meanings
Code & Repository
The full code for this tutorial is available on GitHub. You can follow along by running the code locally — it includes everything you need.
Introducing the Movies Dataset
We'll be using a dataset of movies (movies.csv), which contains movie titles and descriptions for 50 movies. The descriptions will be converted into vectors to capture their meaning. This is great for testing semantic search — e.g., find movies similar to a query by theme or plot.
1. Get Familiar with the Dataset
Familiarize yourself with the movies dataset (movies.csv).
2. Generate Vector Embeddings
We'll leverage Azure AI Foundry, which offers a wide selection of pre-trained foundation models hosted on Azure. For our use case, we'll use text-embedding-3-small to convert movie descriptions into high-dimensional vector representations.
This code uses the Azure-hosted OpenAI embedding model - text-embedding-3-small to generate vector embeddings for each movie description in the DataFrame. It stores each embedding in a new column called embedding
from openai import OpenAI
endpoint = "<replace-with-your-endpoint>"
deployment_name = "<replace-with-your-deployment_name>"
api_key = "<replace-with-your-api-key>"
client = OpenAI(
base_url = endpoint,
api_key = api_key,
)
descriptions = df["description"].astype(str).tolist()
embeddings = []
for description in descriptions:
response = client.embeddings.create(
input=description,
model=deployment_name
)
embeddings.append(response.data[0].embedding)
df["embedding"] = embeddings
print(df)3. Setup Elasticsearch
- Run Elasticsearch using Docker
docker-compose up -d
- Configure the index to include a
dense_vectorfield for storing embeddings. Thesimilarityparameter is set tol2_norm, which uses the Euclidean distance to measure similarity between vectors — smaller distances indicate higher similarity.
index_name = "movies"
mapping = {
"mappings": {
"properties": {
"movie_title": {
"type": "text"
},
"description": {
"type": "text"
},
"embedding": {
"type": "dense_vector",
"index": True,
"similarity": "l2_norm"
}
}
}
}4. Index Data into Elasticsearch
- Index each movie with its title, description and vector embedding using Elasticsearch Bulk API
index_name = "movies"
def create_documents(df):
for row_index, row_data in df.iterrows():
movie_title = row_data["movie_title"]
description = row_data["description"]
embedding_vector = list(row_data["embedding"])
yield {
"_index": index_name,
"_id": row_index,
"_source": {
"movie_title": movie_title,
"description": description,
"embedding": embedding_vector
}
}
helpers.bulk(es, create_documents(df))
print(f"Inserted {len(df)} documents into Elasticsearch index '{index_name}'.")This lets Elasticsearch store both the text and semantic representation.
5. Perform Vector Search Queries
Now that the index is set up and populated with both textual and vector data, we can move onto the core functionality — performing vector search queries.
- Convert a user's query text into a vector using the same pre-trained model -
text-embedding-3-small - Use Elasticsearch's k-NN (k-Nearest Neighbors) query to find movies whose embeddings are closest to the query vector
query_text = "A man finds out his world is fake and tries to escape it"
embedding_response = client.embeddings.create(
input=query_text,
model=deployment_name
)
query_vector = embedding_response.data[0].embedding
body = {
"size": 3,
"query": {
"knn": {
"field": "embedding",
"query_vector": query_vector,
}
}
}
response = es.search(index=index_name, body=body)
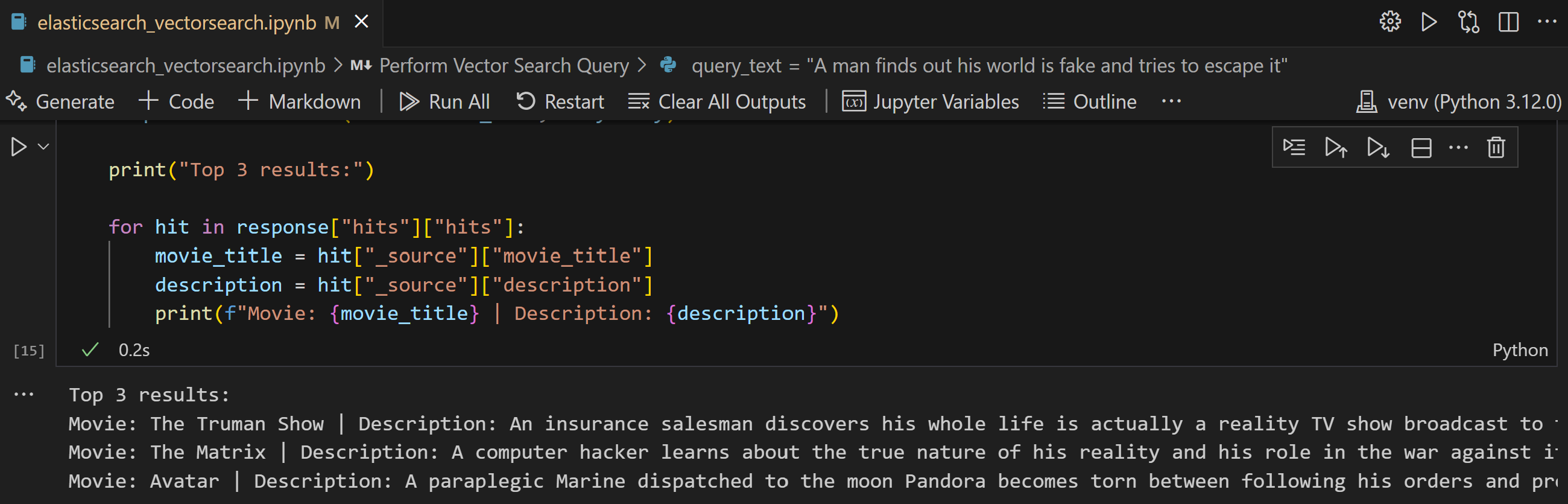
print("Top 3 results:")
for hit in response["hits"]["hits"]:
movie_title = hit["_source"]["movie_title"]
description = hit["_source"]["description"]
print(f"Movie: {movie_title} | Description: {description}")Notice the query:
"A man finds out his world is fake and tries to escape it"
The query correctly returns The Truman Show, The Matrix and Avatar – because it captures the semantic meaning of the plot, not just the surface-level words.